Scraping the NSA's job listings
September 18, 2023
On January 24th 2023 the National Security Agency (NSA) announced an “Unprecedented Hiring Effort”. Over 3,000 new employees shall be hired following up to it. The NSA Executive Director described it as “critical that we’re able to build and sustain the diverse and expert workforce we need to continue working our missions”.
A few days after the press release I started scraping a JSON endpoint of the website where the job listings are posted. I stumbled across the endpoint in my browser’s network tab and guessed saving the results would be valuable over time since past job listings usually are removed.
In this post I want to present some key findings by looking into this data. I invite you to use the data yourself to gather even more findings.
The source code of the scraper and the resulting data is available on GitHub.
Preface #
For now, 2,032 unique job offers were captured by the scraper.
The scraper runs as a GitHub Actions workflow in my repository riotbib/schlapphut (German for floppy hat: the stereotypical hat of spies). Using Microsoft’s infrasctructure has the advantage that the NSA or other targets would rather not block an IP range from this company. The workflow ran every hour at the 26th minute (not at the first, thus enabling to catch an immediate run in the CI – at least hoping for it) and every day of the week.
The scraper is hugely influenced by Simon Willison’s git-scraping technique: This means a runner is fetching the JSON endpoint and committing the result. This analysis was also partly done by Simon’s datasette software. Thanks a lot for the work!
Preparation #
Let’s take a look at the raw data. Every scraped job-listings.json (a direct copy of the randomly found JSON endpoint) has streamlined keys to the values. Unique IDs allow distingushing between different job offers.
$ head job-listings.json
[
{
"_id": "64db8dd57ab798cd68ba857b",
"jobNumber": "1215032",
"OtherActivities": null,
"agency": "NSA",
"description": "Signals Analysis is a cutting-edge technical discipline that seeks to identify the purpose, content and user(s) of signals. Given today's rapidly evolving global communications, the NSA must maintain and develop a highly talented and diverse workforce of Signals Analysts who are a vital part in maintaining our technical capabilities to use the most sophisticated means to recover, understand, and derive intelligence from all manner of foreign signals.",
"fullDescription": "Signals Analysis is a cutting-edge technical discipline that seeks to identify the purpose, content and user(s) of signals. Given today's rapidly evolving global communications, the NSA must maintain and develop a highly talented and diverse workforce of Signals Analysts who are a vital part in maintaining our technical capabilities to use the most sophisticated means to recover, understand, and derive intelligence from all manner of foreign signals.",
"grade": "07/1 to 14/10",
"jobAdditionalInformation": null,
Using simonw’s git-history I converte the data from the JSON file and its older version in the git-repo to an SQLite database. The unique ID is used as an identifier.
$ git-history file job-listings.db job-listings.json --id '_id'
[####################################] 343/343 100%
Thus it’s possible to run datasette. An interface will start up to browse, facet and explore the data.
Key findings #
Now, I present you five findings that are easy to gather while exploring the data.
One could go further and explore, wheter the scraped data leaks actual INTEL on the NSA; such as looking into the times, when and what job got listed for the first time.
The employers #
Using the facet agency shows that most jobs are offered by National Geospatial-Intelligence Agency (NGA) and not the NSA.
So far the NGA offered 1,677 jobs with the NSA and 355 job offers being the latter.
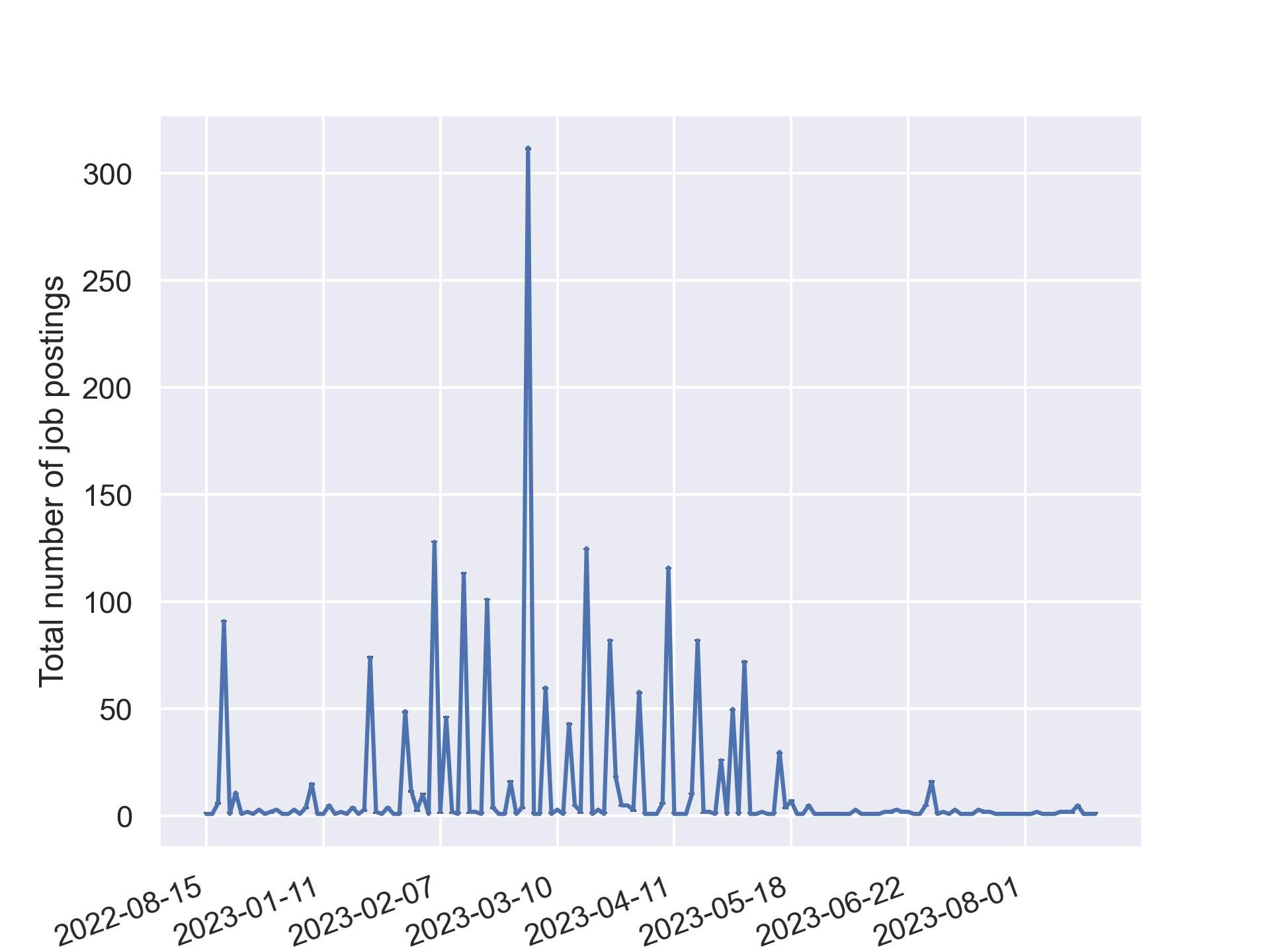
Posted dates #
By plotting the dates the job offers are posted you may see that most jobs have already been listed.
That begs the question, if the intelligence services will follow through with offering those 3,000 jobs they announced in Jan 23.
Job families #
Using the facet jobFamily different main emphasises of the desired working craft is expressed.
The “Other” category is mostly programming jobs, as I explored by scrolling through the so called job family.
| Job Family | Number of listings |
|---|---|
| Intelligence Analysis | 345 |
| Other | 338 |
| Engineering and Physical Sci | 305 |
| Computer Science | 269 |
| Physical Security | 134 |
| Bus., Accntng and Bdgt | 129 |
| Intelligence Collection | 96 |
| Comm. and Public Affairs | 77 |
| Cyber | 56 |
| Language Analysis | 50 |
| Student Programs | 44 |
| Human Resources | 40 |
| Math | 35 |
| General Admin. Support | 32 |
| Infrastructure and Logistics | 22 |
| Inspctn, Invstigtn, Enfrcmnt | 22 |
| Medicl and Occupatnal Hlth | 20 |
| Law and Legal Services | 11 |
| Data Science | 3 |
| Education and Training | 3 |
| Safety & Environmental | 1 |
Common nouns and verbs #
Using NLP such as the library spaCy, I was able to find the most common nouns and verbs presented in the fullDescription column of the data.
Bear in mind, that NLP always got a bias based on the used modell data. Furthermore, HR departments always use such bingo kind of terms for their job offers.
#! /usr/bin/env nix-shell
#! nix-shell -i python3 -p python3Packages.spacy python3Packages.spacy_models.en_core_web_sm
import spacy
from collections import Counter
text = open('job-listings-full-description.txt').read()
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
nouns = [token.text for token in doc if token.pos_ == "NOUN"]
noun_freq = Counter(nouns)
common_nouns = noun_freq.most_common(10)
print(str(common_nouns))
verbs = [token.text for token in doc if token.pos_ == "VERB"]
verb_freq = Counter(verbs)
common_verbs = verb_freq.most_common(10)
print(str(common_verbs))
# Top 10 common nouns
[('data', 675), ('systems', 640), ('requirements', 508), ('services', 416),
('products', 380), ('customers', 376), ('information', 355),
('intelligence', 298), ('security', 272), ('mission', 251)]
# Top 10 common verbs
[('provide', 518), ('develop', 422), ('analyze', 387), ('apply', 353),
('perform', 331), ('ensure', 302), ('oversee', 282), ('conduct', 272),
('evaluate', 239), ('monitor', 174)]
Last words #
This brief article does invite you to explore the data yourself. The scraper will keep running, until it’s blocked or other technical or legal insurmountable hurdles occure. Please do feedback back to me, if you find worthy information in the data.